Re-inventing The Wheel (Or, The Circuit Breaker)
TweetWe occasionally have an issue where a high-traffic third-party endpoint goes down, and our fleet of workers become entirely bogged down by jobs just waiting to time out on that endpoint. This is a common problem, and a common solution is the circuit breaker pattern. If there’s one thing to learn about the Ruby community, it’s where there’s a common solution, there are a lot of gems. Don’t get me wrong: I think that’s part of what makes Ruby, and open source in general, great.
If you’ve worked with Ruby or any other open ecosystem, you might’ve felt like the bulk of the work is just writing glue code. We spend a lot of time gluing together different gems/libraries to create a cohesive system. But we’re software developers, right? We’re certainly capable of writing our apps from scratch, but for some reason we don’t do that very often. If you begin a new web project from scratch, you’ll likely gain an appreciation for Rack and friends. It’s obvious why we tend to use frameworks to build large, complex web applications - it saves a lot of time and effort solving problems that other people have already worked through. Makes sense, but does that apply to adopting smaller libraries? It’s “obvious” that we don’t want to write our own HTTP parser, database, and ORM because some very good ones already exist, but is it “obvious” that we want to use a library for something as simple as Martin Fowler’s circuit breaker pattern?
Breaking down the problem
There are probably many ways to look at this, but these are the tradeoffs I weigh when deciding on whether or not to use a third-party library:
- Amount of code added with library vs. amount of code added with in-house solution.
- Trust in library author vs. confidence in maintainability of in-house solution.
This may seem like a small, trivial decision, but let’s go ahead and over-analyze it.
Code added with library vs. code added with in-house solution.
It’s rare, but if the amount of code introduced in your project due to a library is higher than the total amount of code needed to create and integrate your own solution, then it’s usually pretty easy to argue for creating your own solution.
In our case, the circuit breaker is rather simple in concept, and so the minimum amount of code necessary is pretty low. We have many external requests that need to be guarded, and so the sheer amount of code needed to guard each request starts to run high.
Trust vs. maintainability.
This might seem like apples vs. oranges, but it can be rephrased as “trust in library author” vs. “trust in yourself.” If you can’t trust yourself or your team to maintain an in-house solution, it will likely be unreliable - a fate similar to adopting a poorly maintained library. If the problem you’re trying to solve is hard and outside your expertise, you might want to avoid maintaining your own solution. Conversely, if there are no good third-party solutions out there, maybe it’s a good idea to get down and dirty with the problem. Then maybe you can release your solution to the world.
Knowing how much you can trust a third party can be difficult. Thankfully we Rubyists work in a mostly open source environment, so anyone can be an author, and sustained popularity can be a good source of trust. Another good gauge is documentation. Thorough and up-to-date documentation is a great source of peace of mind when relying on someone else’s work.
How to know when to do it
If there’s no obvious answer to the question of whether or not to adopt a library, one technique I like to use is to implement both at the same time. Copy your whole project directory, then implement your own solution in one and integrate a library in the other. Whenever you hit a bump on one, start working on the other. Eventually, it’ll become clear which approach is nicer and you can safely abandon the other one.
For our circuit breaker system, we wanted to use MySQL to store state. Most libraries either came with Redis, or simply weren’t distributed. Redis seems like the right tool for the job here (I don’t blame folks for just assuming Redis) but we didn’t want to introduce another point of failure, and MySQL is pretty fast compared to the external requests that are prone to timing out. The only difficulty with using MySQL was that if a timeout occurred inside of a transaction, the circuit breaker’s counter would roll back, rendering it useless. We had to make sure the state used a separate MySQL connection from ActiveRecord. That problem would be a bit trickier to tackle had we run into it in a pre-existing library.
Some of the circuit breaker libraries we considered come with a pluggable data store. That seemed great, since it allowed us to choose MySQL. The main issue there was with documentation. While we could choose to use MySQL, there seemed to be no information about how to create or configure the any actual database tables for the data store to use, or whether or not we would run into any issue with transactions. While we certainly could have just read through the source code and figured out how it all works, we would likely want to introduce some tests to make sure everything’s hooked up properly. We figured speccing out and maintaining our own implementation would easier.
Our solution
Even though our circuit breaker solution is not nearly as flexible or feature rich as many existing libraries, we still decided to open source it. It was hard to come up with a name, since the circuit breaker Ruby market is pretty saturated, but we eventually ended up calling it Knifeswitch.
An advantage of assuming a MySQL data store is that we can implement a lot of the circuit breaker logic directly in SQL. Some examples:
/* To increment the counter when a timeout occurs */
INSERT INTO knifeswitch_counters (name,counter)
VALUES (?, 1)
ON DUPLICATE KEY UPDATE counter=counter+1/* To check if the circuit is open */
SELECT COUNT(*) c FROM knifeswitch_counters
WHERE name = ? AND closetime > NOW()These snippets are small enough to include inline, making Knifeswitch’s code easy to review and reason about. Additionally, they might result in an overall lower number of queries when compared to a MySQL plugin for a generic data store system. The tradeoff, of course, is that the library is now pretty tightly coupled to MySQL and would require tweaking if we wanted to switch database backends.
Was it worth it?
Here is simple diagram comparing Knifeswitch to a more-or-less random sample of other circuit breaker gems.
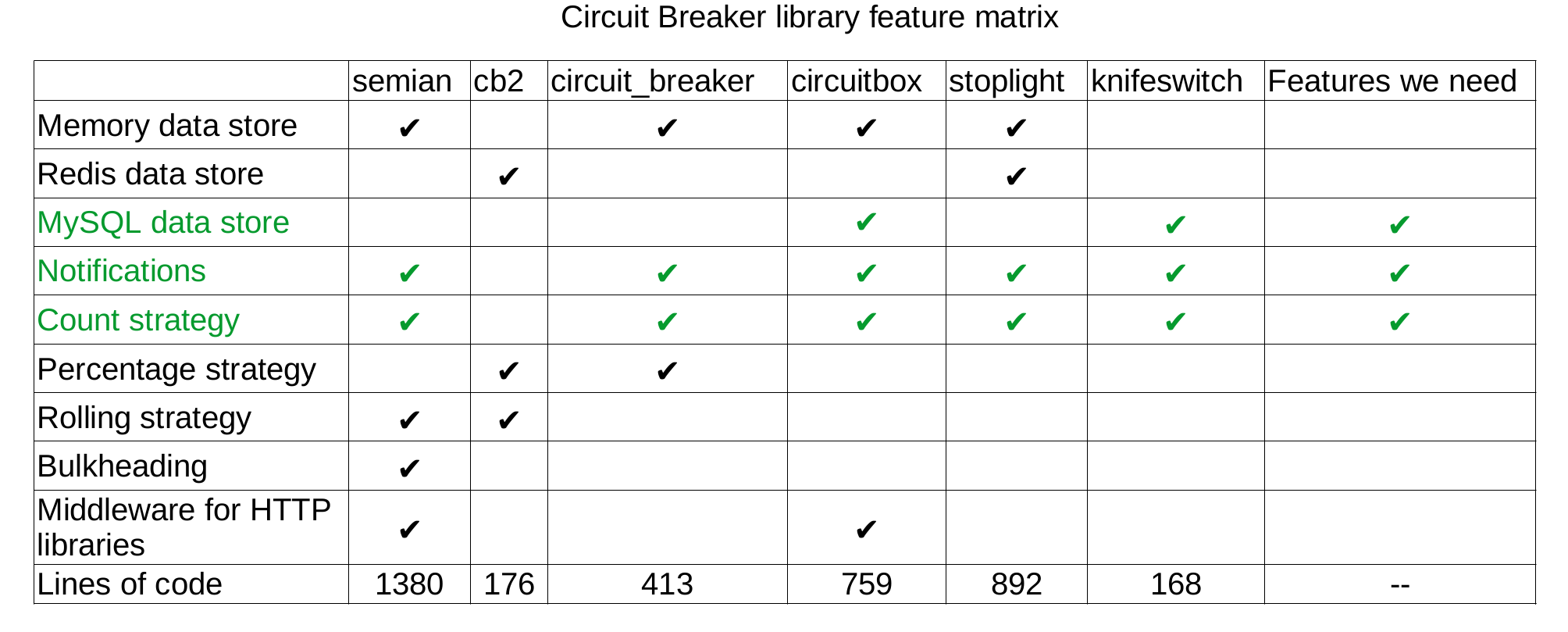
All of these gems have some great features, but we had a hard time finding one that fit our exact requirements. By rolling our own, we now have a clean and concise solution with no unused code. The question of whether or not the in-house gem was worth the time and effort is tricky to answer objectively. Even if it turns out to be a bad idea and we scrap it, we’ll have a much better understanding of the problem. Learning from your mistakes, and all. At the moment, the in-house solution makes a lot of sense and gives us a clear path forward, making it worth it.